Une histoire du web.
Regarder la vidéo suivante :
Fonctionnement du web : url/http
La composition d'une url
Les sites Web ont une structure en arborescence comme vos fichiers sur votre ordinateur. Une ressource (page, photo…) peut se trouver dans un dossier, lui-même situé dans un autre dossier et ainsi de suite.

Une URL (Uniform Resource Locator) est l’adresse d’une ressource d’un site Web : elle indique où elle se trouve dans l’arborescence du site. Elle se compose de 3 grandes parties : le protocole HTTP, le nom de domaine et le chemin vers la ressource.
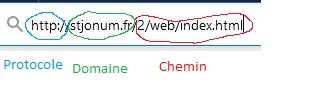
Distinguer les trois parties de l’URL suivante : http://eduscol.education.fr/actualites/article/sciences-numerique-technologie.html
Les requêtes HTTP
Le Web s’appuie sur un dialogue entre clients et serveurs. Les clients sont les applications qui se connectent au Web, comme les navigateurs, qui envoient des requêtes HTTP (HyperText Transfert Protocol) aux serveurs où sont stockées les données. HTTP est le protocole qui permet aux ordinateurs de communiquer entre eux.
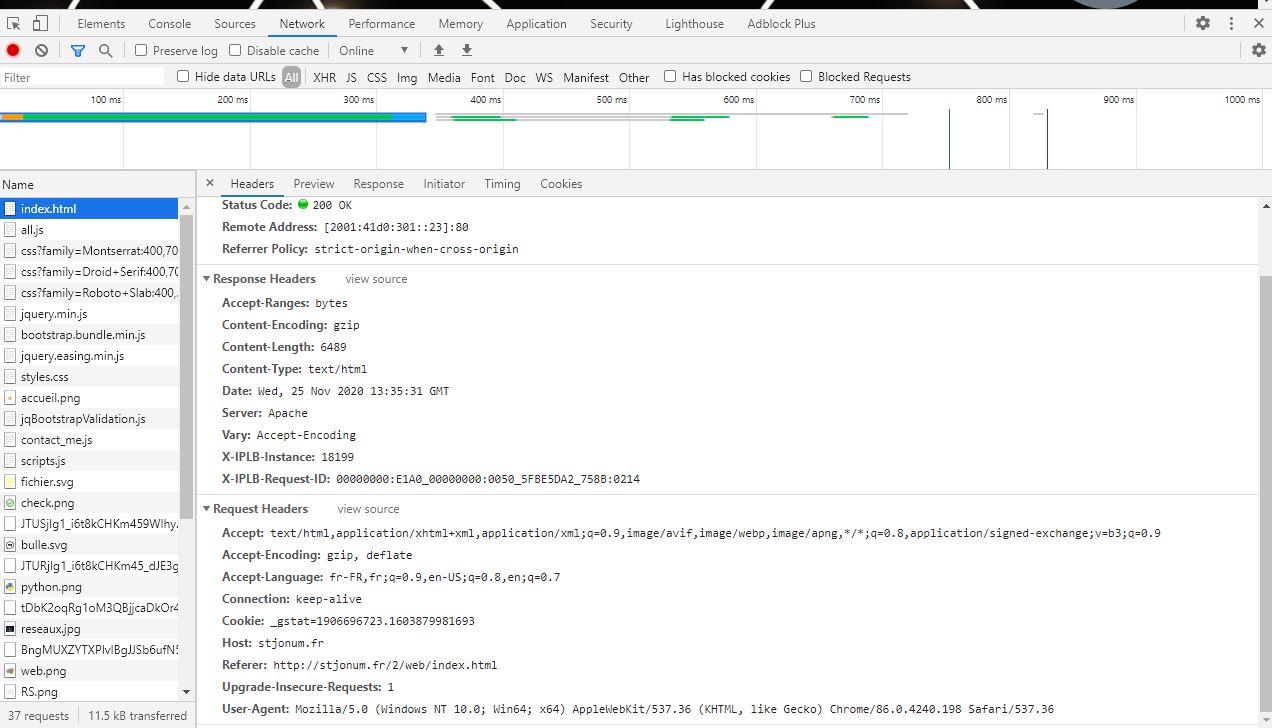
L'interaction client-serveur
Lorsque l’on effectue une requête HTTP sur notre navigateur, le serveur Web lui renvoie du code que le navigateur interprète et met en forme de manière lisible.
Les clients peuvent recevoir des codes exécutables, comme le Java-Script, qui permettent de rendre les pages plus dynamiques.
Ce que nous pouvons voir sur ce cours est le résultat d’une interaction constante entre le serveur et le client
Le protocole HTTP permet de transférer des fichiers mais ne se préoccupent pas du chemin suivi, ce qui rend les informations sensibles, privées
ou financières, vulnérables à une interception et à un détournement.
Pour pallier à ce problème, le protocole de sécurité SSL (Secure Socket Layer) va s'ajouter au protocole HTTP et
crypter les informations entre le serveur et le client. HTTP devient alors HTTPS . Un cadenas  apparaît dans la barre
d'adresse du navigateur pour indiquer que la communication est sécurisée.
apparaît dans la barre
d'adresse du navigateur pour indiquer que la communication est sécurisée.
Attention, HTTPS ne garantit en rien que le site soit un site sûr, seule la communication est sécurisée !
Ainsi, avec le protocole HTTP, un pirate informatique peut intercepter des informations transitant entre le client et le serveur et les lire tandis qu'avec le protocole HTTPS, il peut les intercepter mais ne peut plus les lire.
Les moteurs de recherche
-
Regarder la vidéo ci-dessous
Répondre aux questions suivantes pour vérifier que vous avez compris l'essentiel :
-
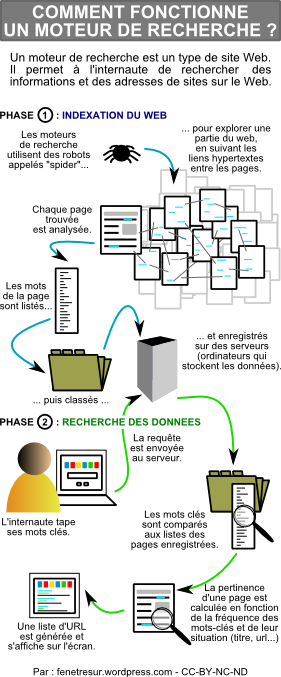
Comment les spiders robots parcourent-ils le Web ?
-
Quel est le rôle de ces robots ?
-
Où sont stockées les informations obtenues par ces spiders ?
-
Comment sont classées les pages comportant les mots-clés d'une recherche ? (hors annonces publicitaires)
-
Tous les résultats affichés sont-ils nécessairement pertinents ? Pourquoi ?
-
Voici un shéma qui résume le fonctionnement d'un moteur de recherche