Manipulation de tables avec la bibliothèque Pandas
Adaptation distanciel
Introduction
Nous avons vu dans l'activité précédente' « Manipulations de tables » comment faire en Python du traîtement de données, à partir notamment de fichiers csv. Mais, bien que les différents programmes présentés soient tous relativement simples, l’enchaînement des étapes de traîtements vont vite conduire à des constructions fastidieux et peu lisibles d’instructions. Pour remédier à ce problème, nous allons utiliser la bibliothèque pandas qui permet d’exprimer de façon simple, lisible et concise de genre de transformations de données. Il faut cependant noter qu’il n’y a rien de magique dans cette bibliothèque, et que les commandes présentées dans le document précédent continuent d’illustrer les traitements de départ. Seulement, dans la bibliothèque pandas, une représentation adaptée des données permet de rendre le tout plus efficace.
Prise en main
Lecture de fichiers
De façon classique en Python, nous allons commencer par charger le module.
import pandas
La lecture d’un fichier csv se fait alors aisément grâce à la commande : notez qu'il faut au préalable détenir le fichier :-) téléchargeable ici!
villes = pandas.read_csv("villes.csv", delimiter=",", keep_default_na=False)
où, en particulier, on spécifie explicitement le caractère utilisé pour délimiter les champs du fichier, ici une virgule. Nous allons voir que la bibliothèque pandas propose quelques commandes utiles :
Testez les différentes commandes dans la console en incluant les commandes dans une variable. Exemple
import pandas
villes = pandas.read_csv("villes.csv", delimiter=",")
x=villes.dtypes
Vous devriez obtenir : (en tapant x dans la console ou en faisant un print)
dep object
nom object
cp object
nb_hab_2010 int64
nb_hab_1999 int64
nb_hab_2012 int64
dens int64
surf int64
long int64
lat int64
alt_min float64
alt_max float64
dtype: object
On remarque en particulier que pandas a reconnu que les champs latitude, longitude et population correspondent à des données numériques, et le traîtent comme tels. On peut aussi avoir des données statistiques (bien sûr, seules celles concernant la population soient pertinentes) en utilisant .describes():
le comportement de describe () est différent avec une série de chaînes(exemple: x=villes["nom"].describe()). Différentes statistiques ont été renvoyées, telles que nombre de valeurs, valeurs uniques, sommet et fréquence d'occurrence dans ce cas.
Dataframes et series
Les tables lues dans les fichiers csv sont stockés par pandas sous forme de dataframes. On peut les voir comme un tableau de p-uplets nommés. Par exemple, l’enregistrement numéro 16767 (obtenu grâce à la méthode loc) s’obtient en exécutant: villes.loc[16767]
dep 44
nom Châteaubriant
cp 44110
nb_hab_2010 12022
nb_hab_1999 12065
nb_hab_2012 12200
dens 357
surf 33
long 62
lat -1
alt_min 38333
alt_max 47
Unnamed: 12 7167
Unnamed: 13 48
Unnamed: 14 107
Name: 16767, dtype: object
On peut facilement isoler des données, par exemple, pour obtenir le nom: villes.loc[16767]['nom']
Interrogation et tris
Les méthodes nlargerst et nsmallest permettent de déterminer les plus grands et plus petits éléments selon un critère donné. Ainsi, pour obtenir les villes les plus grandes en superficie et celles les moins peuplés, on peut écrire :
x=villes.nlargest(10,'dens')
Le tri d’un dataframe s’effectue à l’aide de la méthode sort_values, comme par exemple :
x=villes.sort_values(by='nb_hab_2012')
On peut trier selon plusieurs critères, en spécifiant éventuellement les monotonies. Ainsi, pour classer par cp puis par densité décroissante (avec une sélection pertinente de champs) :
x=villes.sort_values(by=['cp', 'dens'], ascending=[True, False])[ ['cp', 'nom', 'dens']]
Manipulation de données
Après ce survol des méthodes de base pour extraire et ordonner les données contenue dans une table, nous allons pour finir voir quelques méthodes de manipulation de tables.
création de champ
Il est très facile de créer de nouveaux champs à partir d’anciens. Par exemple, pour calculer la densité de chaque villes, il suffit d’exécuter :x=villes['densité'] = villes.nb_hab_2012 / villes.surf
Répondez aux questions sur le dépôt (utilisez des copies d'écran pour montrer votre code ou copier/coller le.
Il est possible de fusionner 2 tableaux de données qui ont une colonne commune :
Afin de travailler sur cette fusion, nous allons travailler avec 2 fichiers au format CSV : fiches_client.csv et fiches_com.csv.
La fusion
Après avoir téléchargé les 2 fichiers ci-dessus, testez le code suivant :
import pandas
client=pandas.read_csv("fiches_client.csv")
commande=pandas.read_csv("fiches_com.csv")
Vous devriez normalement obtenir pour "client" :
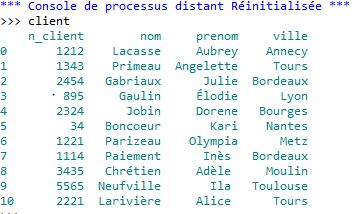
et pour "commande" :
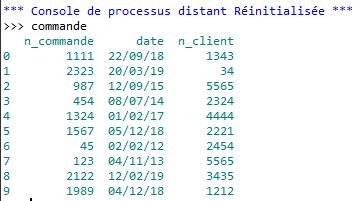
Rien de bien complexe, nous avons un tableau qui référence les clients (nom, prénom, ville), chaque client possède un numéro de client. Le deuxième tableau référence des commandes : pour chaque commande, nous avons un numéro de commande, une date et le numéro du client qui a passé la commande, ce numéro de client correspond évidemment au numéro de client que l'on trouve dans le premier tableau.
Sachant que nous avons deux colonnes contenant les mêmes types d'information (numéros de client), nous allons pouvoir fusionner les deux tableaux en un seul :
Testez le code suivant :
import pandas
client=pandas.read_csv("fiches_client.csv")
commande=pandas.read_csv("fiches_com.csv")
cl_com=pandas.merge(client, commande)
Afficher le contenu de la variable "cl_com"
Vous devriez obtenir ceci :
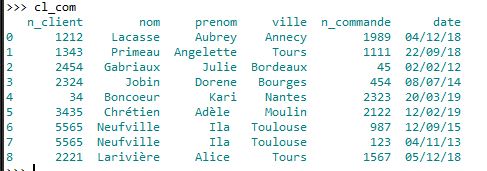
Prenons l'exemple de Mme Julie Gabriaux qui habite à Bordeaux (n° de client 2454) et de la commande effectuée le 02/02/2012 par le client ayant le n° 2454 (commande n° 45). La cliente qui a passé cette commande n° 45 est bien Mme Gabriaux, nous avons une ligne dans notre tableau "cl-com" :

Nous avons bien fusionné les 2 tableaux "client" et "commande" en un seul tableau "cl_com" qui regroupe les informations pour chaque commande. Quand on effectue ce genre de fusion, on dit souvent que l'on effectue une jointure.
Il faut prendre garde à l'ordre des arguments de la fonction "merge" :
Testez le code suivant :
import pandas
client=pandas.read_csv("fiches_client.csv")
commande=pandas.read_csv("fiches_com.csv")
com_cl=pandas.merge(commande, client)
Afficher le contenu de la variable "com_cl"
Vous devriez obtenir ceci :
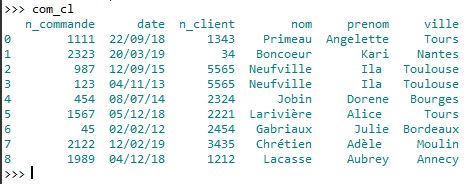
Comme vous pouvez le constater, l'ordre des colonnes est différent. Il faudra donc être attentif à l'ordre des paramètres de la fonction "merge".
Remarque : On trouve Mme Ila Neufville sur 2 lignes, car elle a passé 2 commandes.
Vous avez peut-être remarqué que Mme Élodie Gaulin (n° de client 895) bien que présente dans le tableau "client", est absente du tableau "com_cl" (ou "cl_com"). Pourquoi d'après vous ?
De la même manière, aucun trace de la commande n° 1324 du 01/02/2017 dans le tableau "com_cl" (ou "cl_com"), pourquoi d'après vous ?
Comme nous venons de le voir ci-dessus, il faut que l'élément qui permet la jointure (ici un numéro de client) soit présent dans les 2 tableaux
Tracés de graphiques
La bibliothèque pandas permet également de réaliser toutes sortes de graphiques en exploitant les bibliothèques numpy et matplotlib :
import pandas
import numpy
import matplotlib.pyplot as plt
villes = pandas.read_csv("cities.csv", delimiter=";")
Les séries peuvent faire l’objet de graphiques.
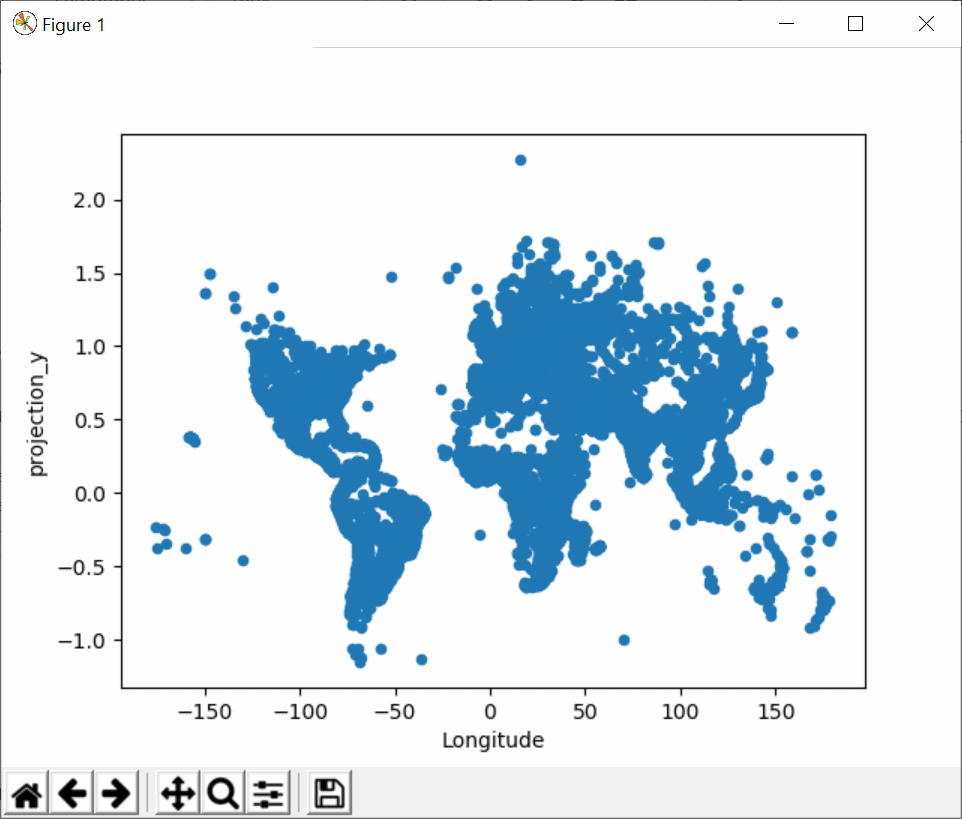
Par exemple, on peut réaliser une carte des villes utilisant la projection de Mercator en effectuant :
villes['projection_y'] = numpy.arcsinh(numpy.tan(villes.Latitude * numpy.pi / 180)) villes.plot.scatter(x='Longitude', y='projection_y') plt.show()
Conclusion
La bibliothèque pandas que nous avons présentée dans ce document est un outil intéressant pour s’initier à la manipulation de données. En particulier, le rôle central qu’y jouent les dataframes permet de manipuler les enregistrements quasiment comme s’il s’agissait de p-uplet nommés. Dans cette séquence nous n'avons abordé que le début de manipulation de tables, c'est en terminale que nous exploiterons plus en profondeur cette manipulation pour exploiter au mieux les "datas"
Pour aller plus loin...
Amusez vous à traiter des tables de votre choix en imaginant une problématique