C'est quoi l'ASCII, l'UNICODE, l'UTF-8 ?
L’ordinateur est un système « tout numérique » il ne manipule que des 0 et des 1. il faut donc trouver un moyen de représenter les lettres sous forme de nombre. Quel nombre on prend pour représenter la lettre 'A' ? Et pour les signes de ponctuation ? Il existe différentes conventions (ou codes). L'un des plus connus est le code ASCII (American Standard Code for Information Interchange). C'est un standard américain, mais c'est l'un des plus utilisés sur la plupart des ordinateurs. Le code ASCII définit précisément la correspondance entre symboles et nombres :
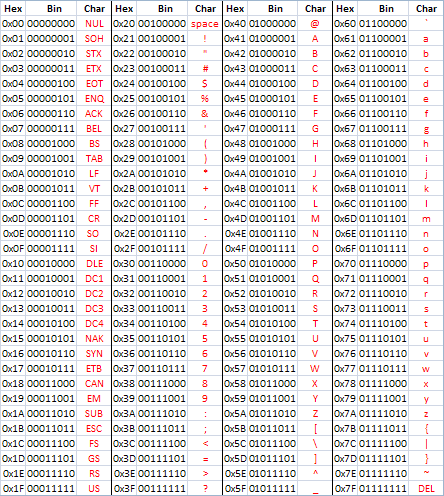
Comme vous pouvez le constater dans le tableau ci-dessus, au "A" majuscule correspond le code binaire (1000001)2 ((65)10 ou (41)16)
- essayez de cracker le code (indice: 54 75 5F 65 73 5F 64 61 6E 73 5F 6C 61 5F 6D 61 74 72 69 63 65 21 )
L'Unicode (www.unicode.org )
Au lieu d'utiliser seulement les codes 0 à 7F sur 8 bits , il utilise des codes bien plus grands qui peuvent aller jusqu’à 32 bits. L’UNICODE permet de représenter tous les caractères spécifiques aux différentes langues. Caractères latins (accentués ou non), grecs, cyrillics, arméniens, hébreux, thaï, hiragana, katakana... L'alphabet Chinois Kanji comporte à lui seul 6879 caractères. L'Unicode définie donc lui aussi une correspondance entre symboles et code binaire. (Le symbole Ő sera représenté par le code bin/hexa 00D2).
Voici des extraits de tables UNICODE (les nombres sont présentés en notation hexadécimal):
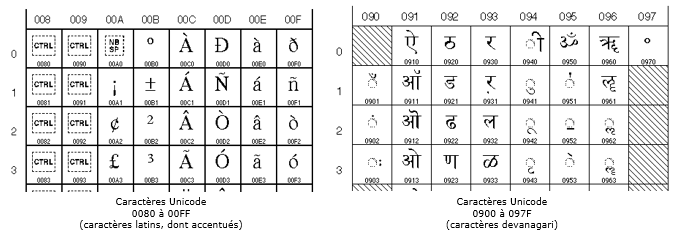
Unicode dans la pratique: UTF-8
Bon. Unicode, dans la théorie, c'est très bien. Mais dans la pratique, c'est une autre paire de manches: Généralement en Unicode, un caractères prend 2 octets. Autrement dit, le moindre texte prend deux fois plus de place qu'en ASCII. C'est du gaspillage. De plus, si on prend un texte en français, la grande majorité des caractères utilisent seulement le code ASCII. Seuls quelques rares caractères nécessitent l'Unicode.
On a donc trouvé une astuce: l'UTF-8.
Un texte en UTF-8 est simple: il est partout en ASCII, et dès qu'on a besoin d'un caractère appartenant à l'Unicode, on utilise un caractère spécial signalant "attention, le caractère suivant est en Unicode". Par exemple, pour le texte "Bienvenue chez Sébastien !", seul le "é" ne fait pas partie du code ASCII. On écrit donc en UTF-8:
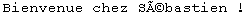
L'UTF-8 rassemble le meilleur de deux mondes: l'efficacité de l'ASCII et l'étendue de l'Unicode. D'ailleurs l'UTF-8 a été adopté comme norme pour l'encodage des fichiers XML. La plupart des navigateurs récents supportent également l'UTF-8 et le détectent automatiquement dans les pages HTML.
Alors dans les pages web, comment on fait ?
Si vous mettez directement le caractère "é" dans une page web, ce n'est pas bien. ll faut obligatoirement choisir une des solutions suivantes:
- soit utiliser les entités HTML, et donc mettre é à la place de "é".
- soit laisser le "é" tel quel et préciser le charset dans la partie
<head>du fichier HTML :
<meta charset=ISO-8859-1"> ou <meta charset=UTF-8">
Traduire en unicode 8: Hello!
utilisez la page suivantecommencez par \ puis séparez les caractères par \
Travailler sur le code des caractères :
Les fonctions python chr(codeASCII) et ord(car) permettent de travailler sur le code ASCII/Unicode d'un caractère.(seule la première ligne est à écrire dans l'éditeur, les suivantes sont à écrire dans la console)
car='A'
ord(car)
65 #Ici le code ASCII est donné sous forme décimale
ord('A')
65 #Ici le code ASCII est donné sous forme décimale
chr(66)
'B'
Convertir le format décimal en héxadécimal ou en binaire
Les fonctions python bin(nombre) et hex(nombre) renvoient une chaîne de caractère représentant respectivement la représentation binaire et hexadécimale du nombre passé en paramètre.(seule la première ligne est à écrire dans l'éditeur, les suivantes sont à écrire dans la console)
code = ord('A')
code
65 # Code en décimal
bin(code)
'0b1000001' # Code en binaire (vous remarquerez qu'il commence par '0b')
bin(code)[2:].zfill(8)
'1000001' # Code sans le préfixe 0b (voir le rôle de la méthode zfill(8)
hex(code)
'0x41' # Code en hexa (vous remarquerez qu'il commence par '0x')
hex(code)[2:]
'41' # Code sans le préfixe 0x